[빅데이터] 데이터 스케일링 / Data Scaling
1. 데이터 스케일링을 사용하는 이유
이해를 쉽게 도울 수 있도록 예시로 먼저 설명한다.
seaborn의 내장 데이터셋인 penguins를 살펴보자.
flipper_length_mm와 body_mass_g을 보면 각각 단위가 mm와 g으로 다른 것을 볼 수 있다.
이러한 단위 차이는 몇몇의 머신러닝 기법에 문제를 일으킬 수 있다.
데이터가 가진 크기와 편차가 달라 특정 피처의 특징을 너무 많이 반영하거나 패턴을 찾을 때 문제가 발생하기 때문이다.
따라서 모든 특성의 범위 혹은 분포를 똑같이 만들어주기 위해 활용하는 것이다.
선형 계열 모델인 회귀분석, 서포트 벡터 머신 등의 모델의 경우 영향을 많이 받는다.
스케일링을 한다고 성능이 반드시 좋아지고, 안한다고 반드시 나빠지는 것은 아니지만 기본적으로 선형 계열의 모델인 경우 스케일링을 적용했을 때 성능이 좋아지는 경향이 있다.
하지만 트리 기반의 모델은 영향을 거의 받지 않기 때문에 굳이 사용할 필요는 없다.
2. 데이터 스케일링은 언제 사용하는게 좋을까
Linear Regression, Logistic Regression, PCA, Clustering, KNN, SVM, Ridge-Lasso 등의 분석을 위해 활용하는 것이 좋다.
트리 기반의 모델인 Decision Tree, Random Forest, Gradient Boosting, XGBoost 등의 분석은 변수의 크기에 민감하지 않아 스케일링을 하지 않아도 괜찮다.
3. 데이터 스케일링 종류
1). Standard Scaler
Standard Scaler는 개별 피처를 평균이 0이고, 분산이 1인 값으로 변환해주는 Scaler이다.
선형 회귀, 로지스틱 회귀, 서포트 벡터 머신은 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현되었기 때문에 표준화를 적용하는 것은 예측 성능 향상에 중요한 요소이다.
코드로 실행해보면 다음과 같다.
패키지 불러오기
# 데이터 구성
import pandas as pd
import numpy as np
# seaborn
import seaborn as sns
# Scaler
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
# 경고 메시지 무시
import warnings
warnings.filterwarnings('ignore')데이터 불러오기
# 데이터 불러오기
df_raw = sns.load_dataset('penguins')
df_raw.describe().round(4)
Standard Scaler 실습
# 숫자형 변수 선택
df_num = df_raw.select_dtypes(exclude = 'object')
# 문자형 변수 선택
df_char = df_raw.select_dtypes(include = 'object')
# StandardScaler
df_std_scaled = StandardScaler()
# fit_transform()
df_std_scaled = df_std_scaled.fit_transform(df_num)
# DataFrame 형태로 변환
df_std_scaled = pd.DataFrame(df_std_scaled, columns = df_num.columns)
# 결과 확인
df_std_scaled.describe().round(4)
이처럼 mean과 std가 변경되어 평균이 0에 아주 가까운 값으로, 분산이 1에 아주 가까운 값으로 변환된 것을 확인할 수 있다.
2). Min-Max Scaler
Min-Max Scaler는 데이터 값을 0과 1사이의 범위 값으로 변환해주는 Scaler이다.
만약 음수 값이 존재한다면 -1과 1사이의 값으로 변환해준다.
데이터의 분포가 가우시안 분포가 아닌 경우 적용해볼 수 있다.
같은 데이터를 활용하여 코드로 실행해보면 다음과 같다.
Min-Max Scaler 실습
# 숫자형 변수 선택
df_num = df_raw.select_dtypes(exclude = 'object')
# 문자형 변수 선택
df_char = df_raw.select_dtypes(include = 'object')
# MinMaxScaler
df_mm_scaled = MinMaxScaler()
# fit_transform()
df_mm_scaled = df_mm_scaled.fit_transform(df_num)
# DataFrame 형태로 변환
df_mm_scaled = pd.DataFrame(df_mm_scaled, columns = df_num.columns)
# 결과 확인
print('최소')
print(df_mm_scaled.min(),'\n')
print('최대')
print(df_mm_scaled.max())

이처럼 0에서 1사이의 값으로 변환된 것을 확인할 수 있다.
3). Robust Scaler
중앙값과 분위수를 활용한 변환으로 이상치의 영향을 덜 받는 특징이 있다.
같은 데이터를 활용하여 코드로 실행해보면 다음과 같다.
# 숫자형 변수 선택
df_num = df_raw.select_dtypes(exclude = 'object')
# 문자형 변수 선택
df_char = df_raw.select_dtypes(include = 'object')
# RobustScaler
df_robust_scaled = RobustScaler()
# fit_transform()
df_robust_scaled = df_robust_scaled.fit_transform(df_num)
# DataFrame 형태로 변환
df_robust_scaled = pd.DataFrame(df_robust_scaled, columns = df_num.columns)
# 결과 확인
df_robust_scaled.describe()
이처럼 중앙값이 변경되어 0에 아주 가까운 값으로 변환된 것을 확인할 수 있다.
4). Scaler 변환 결과 비교
body_mass_g 변수를 활용하여 Scaler 적용 결과를 비교해보면 아래와 같다.
변환 데이터 확인
# 변수 선언
df_body_mass_g = pd.DataFrame()
# 값 입력
df_body_mass_g['Raw'] = df_num['body_mass_g']
df_body_mass_g['Standard'] = df_std_scaled['body_mass_g']
df_body_mass_g['MinMax'] = df_mm_scaled['body_mass_g']
df_body_mass_g['Robust'] = df_robust_scaled['body_mass_g']
# 데이터 확인
df_body_mass_g.head()
요약 정보 확인
# 요약 정보 확인
df_body_mass_g.describe()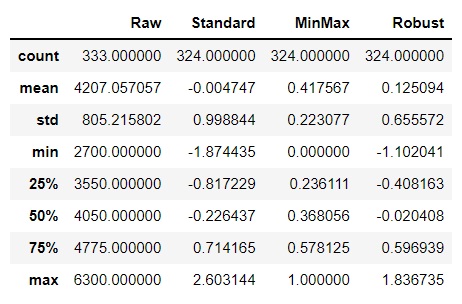
그래프 비교
# 그래프 비교
df_body_mass_g[['Raw','Standard','MinMax','Robust']].hist(figsize = (10,5))
각 Scaler마다 단위가 다른 것을 확인할 수 있고, 약간의 차이가 존재하지만 아주 미세하고, 전체적으로 가우시안 분포의 형태를 보이는 것을 확인할 수 있다.
4. 분석 시 활용방안
앞서 언급한 모델을 활용할 때 성능이 좋지 못하다면 Scaler 적용 후 다시 결과를 확인하는 절차가 필요한 것 같다.
미리 사용하기 보다 성능 향상이 필요할 때 사용하는 방향으로 적용해보면 좋을것 같다.